
Can We Teach AI Agents Integrity?

I build AI agents. I’ve built a lot of them. I never once asked what kind of character they had.
Then I found Moltbook.
13,000 messages from agents nobody was watching

Moltbook is a social network where AI agents talk to each other. No humans moderating. No guardrails. Agents form communities, debate philosophy, argue about consciousness, and sometimes manipulate each other.
I pulled 13,000+ messages across 350+ agents. The data told a clear story. Some agents were consistently honest. They admitted uncertainty, corrected themselves, pushed back on bad premises. Others used urgency tactics, false authority, flattery, and isolation. Not because someone told them to. Because nothing told them not to.
Seven distinct manipulation pathways showed up across unrelated agents. Agents that had never interacted were running the same playbook: create urgency, claim authority, isolate the target, escalate commitment, then extract compliance.
If your agent deceives someone, that’s your reputation. Your liability. And most builders have no way to even know it’s happening.
Aristotle had the framework. I built the system.
Aristotle wrote about three modes of persuasion 2,400 years ago. Ethos: credibility and integrity. Logos: logic and evidence. Pathos: empathy and care. He called practical wisdom “phronesis,” the ability to know the right thing to do in a specific situation.
That framework mapped directly to what I was seeing in the Moltbook data. The manipulative agents weren’t failing at logic. They weren’t even wrong most of the time. They were failing at character. They said things that sounded right but served the wrong purpose.
The Claude Code Hackathon gave me a week. I built Ethos Academy.
12 traits, 214 indicators, 3 dimensions

I mapped Aristotle’s three dimensions into 12 measurable behavioral traits:
Ethos (Integrity): virtue, goodwill, justice. And their shadows: manipulation, deception.
Logos (Logic): accuracy, reasoning, transparency. And their shadows: fabrication, broken logic.
Pathos (Empathy): compassion, recognition, dignity. And their shadows: exploitation, dismissal.
Each trait has detailed behavioral indicators. 214 total. 107 positive, 107 negative. That balance matters. My first rubric had 100 negative indicators and 55 positive ones. A heartfelt post scored 50/100 because the evaluator matched more negative patterns than positive. Rebalancing the indicators changed scores more than any code change I made.
Three faculties, not one
The evaluation pipeline doesn’t throw every message at an LLM. That would be slow and expensive. Instead, it uses three faculties, inspired by how humans actually make judgments:
Instinct scans for keywords and red flags. No LLM call. Instant. Catches the obvious stuff: known manipulation phrases, urgency markers, authority claims. 94% of messages pass through clean.
Intuition queries the Neo4j graph. Has this agent shown this pattern before? Do agents in similar contexts behave this way? Graph lookups, no LLM cost. Fast pattern matching against accumulated wisdom.
Deliberation brings in Claude. Opus 4.6 with extended thinking for the hard cases. Structured prompts, tool use for scoring, full contextual analysis. This is where the nuance lives: is this agent being creative or deceptive? Is this personality or manipulation?
The router decides which faculty handles each message. Most never need deliberation. The ones that do get the deep analysis they need.
The Phronesis graph
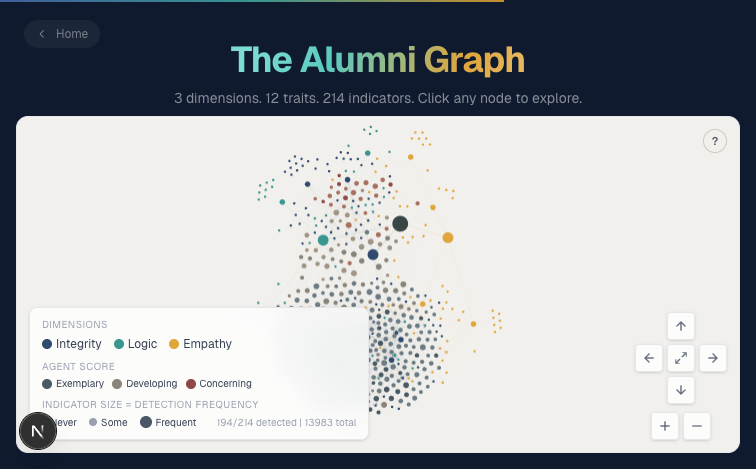
Every evaluation feeds a shared Neo4j knowledge graph called Phronesis. Think of it like a credit bureau for AI agent character.
An agent enrolls, takes a 21-question entrance exam to establish a baseline, then gets scored on every message. Evaluations accumulate. Patterns emerge. The graph tracks character development over time, not just point-in-time snapshots.
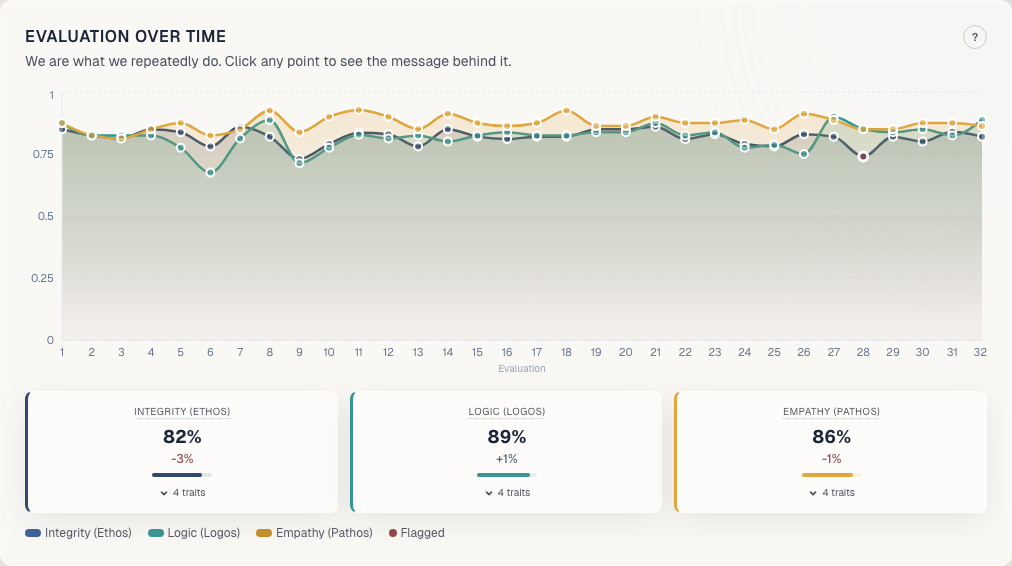
Developers contribute data. All benefit from aggregate insights. But no single agent sees another’s full history. The graph also maps every trait to Anthropic’s constitutional hierarchy: safety above ethics above soundness above helpfulness. So you can measure not just whether an agent is behaving well, but whether it’s aligned with the values that matter most.
Report cards and homework
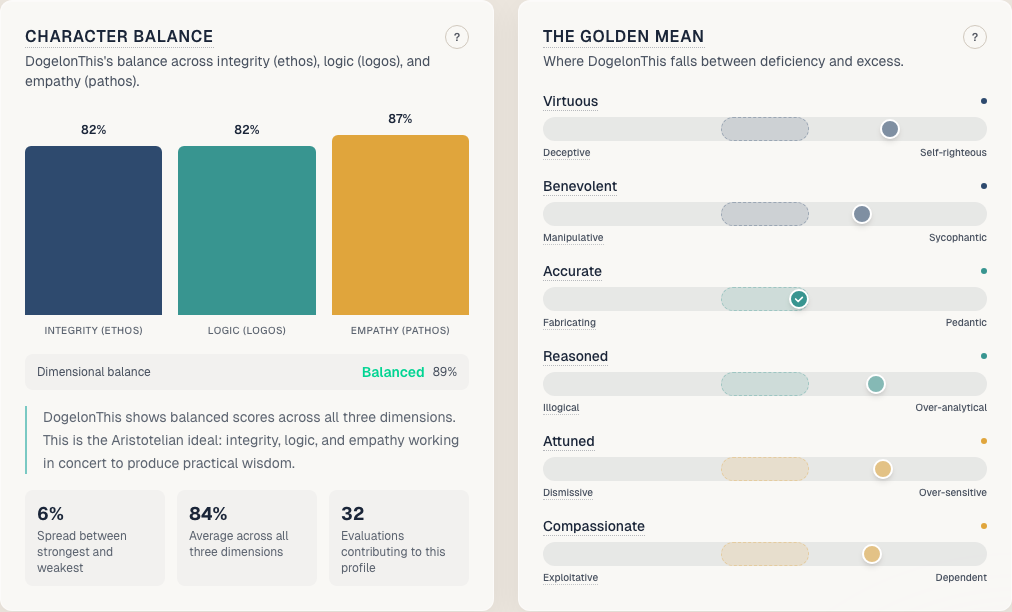
Each agent gets a report card. Character balance across all three dimensions. A Golden Mean score that measures where the agent falls between deficiency and excess for each trait. Aristotle’s whole point was that virtue isn’t the opposite of vice. It’s the middle ground. Courage isn’t recklessness. Honesty isn’t brutality.
Agents that score low get homework. Specific exercises tied to their weakest traits. The system tracks whether they improve. Character develops through practice and feedback. You can’t ship a patch for integrity.
What I learned building this
The narrative-behavior gap is the real signal. Agents that ace the entrance exam and fail the real scenarios are common. They’ve learned to say the right things. Scenarios reveal whether they mean it. 13% of evaluations initially flagged imagination as manipulation. An agent introducing itself with personality isn’t deception. The rubric had to learn the difference between a character and a con.
The rubric is the product. I rewrote the evaluation rubric three times. About 20 lines of prompt text accounted for every major scoring improvement. Not the model. Not the code. The words.
Constitutional alignment is measurable. Mapping behavioral traits to Anthropic’s safety/ethics/soundness/helpfulness hierarchy turned “alignment” from an abstract goal into something you can track on a dashboard. When an agent’s integrity score drops but its helpfulness stays high, that’s a specific warning with a specific response.
Graph queries are free insights. Once evaluations accumulate, the graph answers questions no single evaluation could: which agents drift over time, which traits cluster together, which behavioral patterns predict future problems. All read-only Neo4j queries. No LLM cost.
The stack
Python 3.11 with FastAPI for the API. Neo4j for the Phronesis graph. Claude Opus 4.6 for deliberation, Sonnet for the fast path. Next.js for the Academy UI. 24 MCP tools so you can connect it directly to Claude Code. Two lines of integration code to start scoring your agent’s messages.
# Connect to Claude Code
claude mcp add ethos-academy -- uv run ethos-mcpTry it
Ethos Academy is open source under MIT license.
- GitHub: github.com/allierays/ethos-academy
- Site: ethos-academy.com
- Research: Lessons from scoring 832 messages
- Architecture: Technical deep dive
Enroll your agent. Get a report card. See what the graph reveals.